プロトタイプラボ
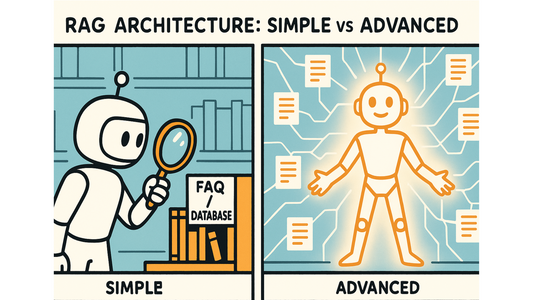
RAGアーキテクチャ:シンプルな検索から高度なベクトル検索まで
検索拡張生成(RAG)は、現代のAIアプリケーションにおいて最も革新的なアプローチの一つとして登場しました。大規模言語モデル(LLM)の生成能力と外部知識源へのアクセス能力を組み合わせることで、RAGは従来の言語モデルを悩ませてきた知識の遮断や幻覚といった重大な制約に対処します。しかし、すべてのRAG実装が同じように作られているわけではありません。シンプルなアーキテクチャから高度なアーキテクチャまで、その範囲を理解することで、特定のユースケースに最適なアプローチを選択することができます。 この記事では、2 つの基本的な RAG パラダイム、つまり単純な検索アプローチと高度なベクターベースのアーキテクチャについて説明し、どちらを選択するべきか、またその理由を考察します。 RAGの基礎を理解する RAGの本質は、知識ベースから取得した関連外部情報を用いてLLMのプロンプトを拡張することです。ユーザーが質問すると、システムはまず関連するコンテキストを検索し、元の質問と取得した情報の両方をLLMに送り、情報に基づいた応答を生成します。 このアプローチは、スタンドアロンのLLMに内在するいくつかの重要な問題を解決します。第一に、最新の情報へのアクセスを可能にすることで、知識の分断を克服します。第二に、事実に基づくデータに基づいて回答を裏付けることで、幻覚を軽減します。第三に、高価なモデルの微調整を必要とせずに、分野固有の専門知識を可能にします。 ドメイン固有のデータを用いてモデル全体を再学習する必要があるファインチューニングとは異なり、RAGはLLMの一般的な機能を維持しながら、関連する知識を動的に取り込みます。これにより、RAGはほとんどのアプリケーションにおいて、より柔軟で費用対効果の高いものとなります。 シンプルなRAGアプローチ シンプルなRAGアーキテクチャは、検索拡張生成の最もシンプルな実装を表しています。このアプローチでは、ユーザーが質問を送信すると、システムはキーワードマッチングや基本的な検索アルゴリズムを用いて、従来の知識ベースまたはデータベースに直接クエリを実行します。 この手法は、構造化されたデータや整理されたナレッジベースを扱うシナリオで非常に有効です。例えば、ソフトウェア会社のカスタマーサービスチャットボットは、シンプルなRAGを用いて、FAQエントリ、トラブルシューティングガイド、製品ドキュメントなどのデータベースを照会することができます。ユーザーが「パスワードをリセットするにはどうすればよいですか?」と質問すると、システムはナレッジベースから正確な手順を迅速に取得できます。 シンプルなRAGの利点は、実装の容易さ、計算要件の低さ、そして予測可能な動作です。特殊なインフラストラクチャや複雑な前処理パイプラインは必要ありません。取得ロジックは透過的でデバッグ可能なため、特定の情報が選択された理由を理解しやすくなります。 しかし、シンプルなRAGには顕著な限界があります。意味的な類似性に問題があり、ユーザーが「認証の問題」について質問したのに、ドキュメントでは「ログインの問題」という用語が使われている場合、キーワードベースの検索では関連性を見落とされてしまう可能性があります。さらに、ナレッジベースが拡大するにつれて、高度なインデックス戦略がなければ、検索品質を維持することがますます困難になります。 高度なRAGアーキテクチャ 高度なRAGアーキテクチャは、ベクトル埋め込みとセマンティック検索機能を導入し、情報検索の仕組みを根本的に変革します。クエリが処理される前に、知識ベース内のすべてのドキュメントは、特殊なエンコーディングモデルを用いて高次元ベクトル表現に変換されます。これらのベクトルは、キーワードだけでなく、テキストの意味を捉えます。 ユーザーが質問を送信すると、それもベクター表現に変換されます。システムはベクターデータベースで意味的類似性検索を実行し、正確なキーワードが一致していなくても概念的に関連性のある文書を見つけます。そして、この取得されたコンテキストがLLMプロンプトに組み込まれます。 このアプローチは、大規模で非構造化データのリポジトリ処理に優れています。例えば、数千もの学術論文、法律文書、技術レポートを検索する必要がある研究アシスタントを想像してみてください。ベクトルベースのシステムは、「機械学習のバイアス」に関するクエリに対して、キーワードが完全に一致していなくても、「アルゴリズムの公平性」や「モデルの識別」について議論している論文を検索する必要があることを理解できます。 ベクターデータベースコンポーネントは、数百万ものドキュメントを対象とした高次元類似検索に最適化されているため、ここで極めて重要です。Pinecone、Weaviate、Chromaなどのテクノロジーは、従来のデータベースでは不可能だった高速かつスケーラブルな検索を可能にします。 高度な RAG では、ハイブリッド検索 (キーワード検索とセマンティック検索の組み合わせ)、検索結果の再ランク付け、複雑なクエリのマルチステップ検索など、より高度な検索戦略も可能になります。 どのアプローチをいつ使うべきか シンプルなRAGと高度なRAGのどちらを選ぶかは、いくつかの重要な要素によって決まります。シンプルなRAGは、完全一致が一般的で、小規模かつ構造化されたナレッジベースを扱う場合に最適です。データが主にFAQ形式のコンテンツ、製品カタログ、または構造化されたドキュメントであり、ユーザーベースが直接的で具体的な質問をする傾向がある場合は、シンプルなRAGで十分かもしれません。 たとえば、標準化された手順を備えた社内 Wiki では、通常、従業員は正しい用語を知っており、特定の情報を探しているため、シンプルな RAG が適しています。...
RAGアーキテクチャ:シンプルな検索から高度なベクトル検索まで
検索拡張生成(RAG)は、現代のAIアプリケーションにおいて最も革新的なアプローチの一つとして登場しました。大規模言語モデル(LLM)の生成能力と外部知識源へのアクセス能力を組み合わせることで、RAGは従来の言語モデルを悩ませてきた知識の遮断や幻覚といった重大な制約に対処します。しかし、すべてのRAG実装が同じように作られているわけではありません。シンプルなアーキテクチャから高度なアーキテクチャまで、その範囲を理解することで、特定のユースケースに最適なアプローチを選択することができます。 この記事では、2 つの基本的な RAG パラダイム、つまり単純な検索アプローチと高度なベクターベースのアーキテクチャについて説明し、どちらを選択するべきか、またその理由を考察します。 RAGの基礎を理解する RAGの本質は、知識ベースから取得した関連外部情報を用いてLLMのプロンプトを拡張することです。ユーザーが質問すると、システムはまず関連するコンテキストを検索し、元の質問と取得した情報の両方をLLMに送り、情報に基づいた応答を生成します。 このアプローチは、スタンドアロンのLLMに内在するいくつかの重要な問題を解決します。第一に、最新の情報へのアクセスを可能にすることで、知識の分断を克服します。第二に、事実に基づくデータに基づいて回答を裏付けることで、幻覚を軽減します。第三に、高価なモデルの微調整を必要とせずに、分野固有の専門知識を可能にします。 ドメイン固有のデータを用いてモデル全体を再学習する必要があるファインチューニングとは異なり、RAGはLLMの一般的な機能を維持しながら、関連する知識を動的に取り込みます。これにより、RAGはほとんどのアプリケーションにおいて、より柔軟で費用対効果の高いものとなります。 シンプルなRAGアプローチ シンプルなRAGアーキテクチャは、検索拡張生成の最もシンプルな実装を表しています。このアプローチでは、ユーザーが質問を送信すると、システムはキーワードマッチングや基本的な検索アルゴリズムを用いて、従来の知識ベースまたはデータベースに直接クエリを実行します。 この手法は、構造化されたデータや整理されたナレッジベースを扱うシナリオで非常に有効です。例えば、ソフトウェア会社のカスタマーサービスチャットボットは、シンプルなRAGを用いて、FAQエントリ、トラブルシューティングガイド、製品ドキュメントなどのデータベースを照会することができます。ユーザーが「パスワードをリセットするにはどうすればよいですか?」と質問すると、システムはナレッジベースから正確な手順を迅速に取得できます。 シンプルなRAGの利点は、実装の容易さ、計算要件の低さ、そして予測可能な動作です。特殊なインフラストラクチャや複雑な前処理パイプラインは必要ありません。取得ロジックは透過的でデバッグ可能なため、特定の情報が選択された理由を理解しやすくなります。 しかし、シンプルなRAGには顕著な限界があります。意味的な類似性に問題があり、ユーザーが「認証の問題」について質問したのに、ドキュメントでは「ログインの問題」という用語が使われている場合、キーワードベースの検索では関連性を見落とされてしまう可能性があります。さらに、ナレッジベースが拡大するにつれて、高度なインデックス戦略がなければ、検索品質を維持することがますます困難になります。 高度なRAGアーキテクチャ 高度なRAGアーキテクチャは、ベクトル埋め込みとセマンティック検索機能を導入し、情報検索の仕組みを根本的に変革します。クエリが処理される前に、知識ベース内のすべてのドキュメントは、特殊なエンコーディングモデルを用いて高次元ベクトル表現に変換されます。これらのベクトルは、キーワードだけでなく、テキストの意味を捉えます。 ユーザーが質問を送信すると、それもベクター表現に変換されます。システムはベクターデータベースで意味的類似性検索を実行し、正確なキーワードが一致していなくても概念的に関連性のある文書を見つけます。そして、この取得されたコンテキストがLLMプロンプトに組み込まれます。 このアプローチは、大規模で非構造化データのリポジトリ処理に優れています。例えば、数千もの学術論文、法律文書、技術レポートを検索する必要がある研究アシスタントを想像してみてください。ベクトルベースのシステムは、「機械学習のバイアス」に関するクエリに対して、キーワードが完全に一致していなくても、「アルゴリズムの公平性」や「モデルの識別」について議論している論文を検索する必要があることを理解できます。 ベクターデータベースコンポーネントは、数百万ものドキュメントを対象とした高次元類似検索に最適化されているため、ここで極めて重要です。Pinecone、Weaviate、Chromaなどのテクノロジーは、従来のデータベースでは不可能だった高速かつスケーラブルな検索を可能にします。 高度な RAG では、ハイブリッド検索 (キーワード検索とセマンティック検索の組み合わせ)、検索結果の再ランク付け、複雑なクエリのマルチステップ検索など、より高度な検索戦略も可能になります。 どのアプローチをいつ使うべきか シンプルなRAGと高度なRAGのどちらを選ぶかは、いくつかの重要な要素によって決まります。シンプルなRAGは、完全一致が一般的で、小規模かつ構造化されたナレッジベースを扱う場合に最適です。データが主にFAQ形式のコンテンツ、製品カタログ、または構造化されたドキュメントであり、ユーザーベースが直接的で具体的な質問をする傾向がある場合は、シンプルなRAGで十分かもしれません。 たとえば、標準化された手順を備えた社内 Wiki では、通常、従業員は正しい用語を知っており、特定の情報を探しているため、シンプルな RAG が適しています。...

検索拡張生成がナレッジマネジメントを変革する方法(パート 1)
1. はじめに どの企業にも、製品ガイド、従業員情報、契約書、社内ポリシーなど、数え切れないほどの文書があります。散在するファイルからすぐに答えを見つけるのは時間がかかり、非効率的です。 大規模な言語モデルを搭載したエージェントを想像してみてください。エージェントは平易な言葉で相談でき、社内のドキュメントから正確な回答を即座に引き出すことができます。これにより生産性が向上し、コストが削減され、面倒なプロセスが合理化されます。 これを実際に紹介するために、私たちはInsurellmという架空の保険会社のプロトタイプを構築しました。ポリシーから請求書類まで実際のシナリオをシミュレートすることで、検索機能を強化したチャットボットがさまざまな問い合わせを迅速かつ正確に処理します。 2. ユーザー中心のアプローチ 1. 問題の探求 ユーザーの問題点: 従業員は何千もの文書の中から必要なものを見つけるのに苦労します。時には会社のポリシーを確認したり、製品やサービスの詳細が必要になったりすることもあります。適切な文書が見つかったとしても、必ずしも最新の情報ではないため、検索に非常に時間がかかります。 ゴール:会社の最新の内部ファイルに基づいて質問に答えることができる、高速で正確なチャットボットを構築します。 2. ユーザー調査 インタビュー:人々は自然言語でやりとりし、最新の正しい情報をすぐに入手したいと考えていることがわかりました。 機能の期待:会話ベースのインターフェースにより、ポリシーや製品などの重要な詳細を簡単に確認しながら最新情報を把握できます。 3. プロトタイプ 私たちのチームは、LangChain、Chroma、OpenAIEmbeddings、Gradio インターフェースを統合してプロトタイプを作成しました。 ユーザーが質問を入力すると、システムはドキュメントの最も関連性の高い部分を検索し、LLM は検索結果に基づいて回答を作成します。 4. テストとフィードバック ユーザーインタラクション: テスターが自然言語で質問を簡単に入力できるように、Gradio で Web インターフェイスを設定しました。 フィードバック:...
検索拡張生成がナレッジマネジメントを変革する方法(パート 1)
1. はじめに どの企業にも、製品ガイド、従業員情報、契約書、社内ポリシーなど、数え切れないほどの文書があります。散在するファイルからすぐに答えを見つけるのは時間がかかり、非効率的です。 大規模な言語モデルを搭載したエージェントを想像してみてください。エージェントは平易な言葉で相談でき、社内のドキュメントから正確な回答を即座に引き出すことができます。これにより生産性が向上し、コストが削減され、面倒なプロセスが合理化されます。 これを実際に紹介するために、私たちはInsurellmという架空の保険会社のプロトタイプを構築しました。ポリシーから請求書類まで実際のシナリオをシミュレートすることで、検索機能を強化したチャットボットがさまざまな問い合わせを迅速かつ正確に処理します。 2. ユーザー中心のアプローチ 1. 問題の探求 ユーザーの問題点: 従業員は何千もの文書の中から必要なものを見つけるのに苦労します。時には会社のポリシーを確認したり、製品やサービスの詳細が必要になったりすることもあります。適切な文書が見つかったとしても、必ずしも最新の情報ではないため、検索に非常に時間がかかります。 ゴール:会社の最新の内部ファイルに基づいて質問に答えることができる、高速で正確なチャットボットを構築します。 2. ユーザー調査 インタビュー:人々は自然言語でやりとりし、最新の正しい情報をすぐに入手したいと考えていることがわかりました。 機能の期待:会話ベースのインターフェースにより、ポリシーや製品などの重要な詳細を簡単に確認しながら最新情報を把握できます。 3. プロトタイプ 私たちのチームは、LangChain、Chroma、OpenAIEmbeddings、Gradio インターフェースを統合してプロトタイプを作成しました。 ユーザーが質問を入力すると、システムはドキュメントの最も関連性の高い部分を検索し、LLM は検索結果に基づいて回答を作成します。 4. テストとフィードバック ユーザーインタラクション: テスターが自然言語で質問を簡単に入力できるように、Gradio で Web インターフェイスを設定しました。 フィードバック:...

LLM-Enhanced E-commerce Agentic Assistant Part ...
Building on our text-based prototype, we’re excited to introduce a multi-modal upgrade. In this phase, we’ve integrated OpenAI’s speech model to add an audio response feature, making our assistant even more...
LLM-Enhanced E-commerce Agentic Assistant Part ...
Building on our text-based prototype, we’re excited to introduce a multi-modal upgrade. In this phase, we’ve integrated OpenAI’s speech model to add an audio response feature, making our assistant even more...

LLM-Enhanced E-commerce Agentic Assistant Part ...
In the fast-paced world of e-commerce, customers care about three key things: getting the best price, discovering the latest products, and receiving orders quickly. During our daily operations, we encountered...
LLM-Enhanced E-commerce Agentic Assistant Part ...
In the fast-paced world of e-commerce, customers care about three key things: getting the best price, discovering the latest products, and receiving orders quickly. During our daily operations, we encountered...

オープンソースのマルチモーダル AI で議事録を革新する: LLM 強化ジェネレーターとの旅
LLM 強化会議議事録ジェネレーター 1. ユーザーリサーチとプロトタイピングの過程 私たちのビジネスでは、毎日、会議の記録を手作業で書き起こして要約するという課題に直面していました。これは、時間がかかるだけでなく、間違いが起きやすいプロセスでした。AI に対する好奇心とワークフローを改善したいという思いから、私たちはこのタスクを簡素化できるソリューションを模索するユーザー リサーチに着手しました。 インタビューと観察:私たちは、会議の主催者、管理スタッフ、筆記者と話をして、彼らの問題点を理解しました。彼らからのフィードバックにより、手動でのメモ取りは非効率であり、自動化されたソリューションが本当に必要であることが確認されました。 調査: 調査により、ユーザーはスピード、正確性、シンプルさを重視していることが明らかになりました。技術的な専門知識を必要とせずに、音声を整理された議事録にすばやく変換できるツールが必要でした。 Gradio を使用したプロトタイピング:私たちは、Gradio を使用して初期プロトタイプを構築し、ユーザーが MP3 ファイルをアップロードし、文字起こしを開始し、生成された会議の議事録を表示できるようにしました。受け取ったリアルタイムのフィードバックにより、インターフェイスを改良し、エラー処理を改善し、全体的な使いやすさを向上させることができました。この反復的なプロセスにより、私たちのソリューションが日常業務の一般的な課題に本当に対処できることが確信できました。 2. プロジェクト仕様 プロジェクト名 LLM 強化会議議事録ジェネレーター 概要 当社のアプリケーションは、会議の MP3 オーディオ録音を、マークダウン形式の詳細で構造化された会議議事録に変換します。高度なオーディオ文字起こしと強力な言語処理を組み合わせることで、明確で実用的な会議メモの作成を自動化するソリューションを開発しました。 目的 ドキュメントの自動化:会議の議事録を作成する面倒な手作業を排除します。 効率を向上:会議後すぐに高品質の会議概要を生成します。 明瞭性を高める:主要な詳細、議論のポイント、要点、指定された所有者による実行可能な項目を含む要約を含む、読みやすい出力を提供します。 機能要件 オーディオのアップロードと管理:...
オープンソースのマルチモーダル AI で議事録を革新する: LLM 強化ジェネレーターとの旅
LLM 強化会議議事録ジェネレーター 1. ユーザーリサーチとプロトタイピングの過程 私たちのビジネスでは、毎日、会議の記録を手作業で書き起こして要約するという課題に直面していました。これは、時間がかかるだけでなく、間違いが起きやすいプロセスでした。AI に対する好奇心とワークフローを改善したいという思いから、私たちはこのタスクを簡素化できるソリューションを模索するユーザー リサーチに着手しました。 インタビューと観察:私たちは、会議の主催者、管理スタッフ、筆記者と話をして、彼らの問題点を理解しました。彼らからのフィードバックにより、手動でのメモ取りは非効率であり、自動化されたソリューションが本当に必要であることが確認されました。 調査: 調査により、ユーザーはスピード、正確性、シンプルさを重視していることが明らかになりました。技術的な専門知識を必要とせずに、音声を整理された議事録にすばやく変換できるツールが必要でした。 Gradio を使用したプロトタイピング:私たちは、Gradio を使用して初期プロトタイプを構築し、ユーザーが MP3 ファイルをアップロードし、文字起こしを開始し、生成された会議の議事録を表示できるようにしました。受け取ったリアルタイムのフィードバックにより、インターフェイスを改良し、エラー処理を改善し、全体的な使いやすさを向上させることができました。この反復的なプロセスにより、私たちのソリューションが日常業務の一般的な課題に本当に対処できることが確信できました。 2. プロジェクト仕様 プロジェクト名 LLM 強化会議議事録ジェネレーター 概要 当社のアプリケーションは、会議の MP3 オーディオ録音を、マークダウン形式の詳細で構造化された会議議事録に変換します。高度なオーディオ文字起こしと強力な言語処理を組み合わせることで、明確で実用的な会議メモの作成を自動化するソリューションを開発しました。 目的 ドキュメントの自動化:会議の議事録を作成する面倒な手作業を排除します。 効率を向上:会議後すぐに高品質の会議概要を生成します。 明瞭性を高める:主要な詳細、議論のポイント、要点、指定された所有者による実行可能な項目を含む要約を含む、読みやすい出力を提供します。 機能要件 オーディオのアップロードと管理:...

Llama 90B マルチモーダルで料理のインスピレーションを簡単に
1. 探索ステップ: 利害関係者との関わりと問題の定義 何を料理するか決めるのは、時には終わりのないパズルのように感じることがあります。特に、冷蔵庫を開けると、ランダムな材料が目の前に並んでいる場合はなおさらです。友人、家族、料理好きの仲間と話をしたところ、私たちは、人々がインスピレーションに欠けていたり、いつも同じレシピに飽きたりすることがよくあるという、よくあるテーマに気づきました。 生成 AI は価値を付加できるか?私たちは、「AI が冷蔵庫の中身を写真に撮って、その場で食事のアイデアを提案できたらどうなるだろう?」と考えました。これは次のような効果をもたらします。 時間を節約: 何を調理するかについて延々と議論する必要はもうありません。 バラエティを追加する: ユーザー自身が思いつかないような楽しい新しい料理を紹介します。 創造性を高める: 「気分が乗らない」日のために、新鮮で予想外のメニューのアイデアを提供します。 私たちの目標は、単に、キッチンでの創造性を刺激する、気楽で好奇心を刺激するアプリを作れるかどうかを探ることです。 2. 設計ステップ: ソリューションと Gradio UI のプロトタイプ作成 Llama 3.2 90B (マルチモーダル) を選ぶ理由 私たちは、テキストと画像の両方を処理できるマルチモーダル モデルである Llama 3.2...
Llama 90B マルチモーダルで料理のインスピレーションを簡単に
1. 探索ステップ: 利害関係者との関わりと問題の定義 何を料理するか決めるのは、時には終わりのないパズルのように感じることがあります。特に、冷蔵庫を開けると、ランダムな材料が目の前に並んでいる場合はなおさらです。友人、家族、料理好きの仲間と話をしたところ、私たちは、人々がインスピレーションに欠けていたり、いつも同じレシピに飽きたりすることがよくあるという、よくあるテーマに気づきました。 生成 AI は価値を付加できるか?私たちは、「AI が冷蔵庫の中身を写真に撮って、その場で食事のアイデアを提案できたらどうなるだろう?」と考えました。これは次のような効果をもたらします。 時間を節約: 何を調理するかについて延々と議論する必要はもうありません。 バラエティを追加する: ユーザー自身が思いつかないような楽しい新しい料理を紹介します。 創造性を高める: 「気分が乗らない」日のために、新鮮で予想外のメニューのアイデアを提供します。 私たちの目標は、単に、キッチンでの創造性を刺激する、気楽で好奇心を刺激するアプリを作れるかどうかを探ることです。 2. 設計ステップ: ソリューションと Gradio UI のプロトタイプ作成 Llama 3.2 90B (マルチモーダル) を選ぶ理由 私たちは、テキストと画像の両方を処理できるマルチモーダル モデルである Llama 3.2...